

Not the error message you want to see on your database cluster.
A problem with your database server is never pleasant. But with your high availability cluster, it’s obviously a disaster. Recently, we’ve encountered this type of cluster problem twice. Two different customers with seemingly the same issue. That’s why we think more people will benefit from reading about our solution.
Failover fails: “The system could not find the environment option that was entered”
It started the same way with both customers. We had just patched the secondary node of the cluster and wanted to begin working on the primary node. To do this, we first perform a failover so we can free up the primary. But the failover fails.
The cluster role won’t come online on the secondary node. No matter what we try. The cluster log shows a specific error message:
Cluster resource ‘Cluster Name’ of type ‘Network Name’ in clustered role ‘Cluster Group‘ failed. The error code was ‘0xcb’ (‘The system could not find the environment option that was entered.’)
When you start googling, you come up empty-handed. You’ll find multiple cases of this error message, but they’re not failover clustering related:
- Missing Windir systems environment variable
- Corrupt Windows installation
- A 10-year-old Reddit post with someone who had the exact same problem but unfortunately: no solution
After extensive investigation with Procmon, we discovered that two crucial registry values were empty on the secondary:
The values:
- HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\Domain
- HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Services\Tcpip\Parameters\NV Domain
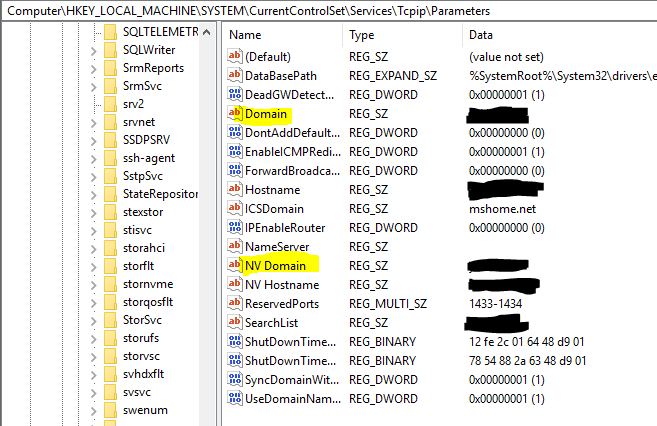
After entering the domain name there and performing a reboot of the secondary, everything worked properly again.
Root cause: “The system could not find the environment option that was entered”
It’s obviously not normal behavior for these registry values to suddenly be empty on a domain member server. We’re therefore still working on finding a scenario where we can reproduce this exactly.
With customer A, it appears to have occurred after a migration from Hyper-V to vSphere, which resulted in the NIC hardware of the cluster nodes being changed.
With customer B, it appears to have occurred after they replaced their DNS servers. As a result, they had to adjust the preferred and alternate DNS server settings on the NICs of the cluster nodes. The problem seems to have emerged after that.
With both customers, the values were only cleared on one node.
We suspect a bug, but the investigation is still ongoing. We’ll provide an update when the root cause is found.